


En el primer post de «IoT4all» exploramos distintas definiciones de Internet de las Cosas y el motivo por el cuál no existe una que podamos considerar como definición canónica. Hoy vamos a hablar de cómo se conectan y comunican los dispositivos IoT, para lo que sí existe un marco perfectamente definido, la RFC7452. En marzo de 2015, el Comité de Arquitectura de Internet (IAB) publicó esta directiva que describe los cuatro modelos de comunicación que vamos a explicar a continuación.
1 Dispositivo a dispositivo, el más común en el hogar
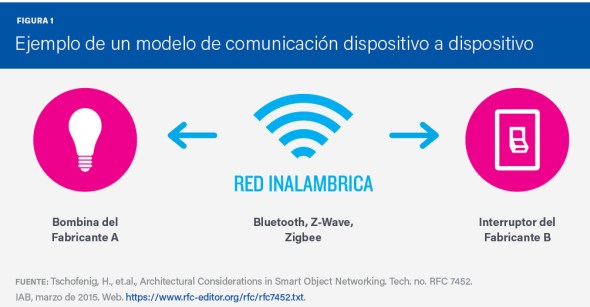
En este modelo, los dispositivos se comunican directamente entre sí, sin necesidad de tener un servidor de aplicaciones intermedio. Esta comunicación puede tener lugar sobre redes IP (Internet), u otro tipo de redes. Muchas veces se utilizan otros protocolos como Bluetooth, Z-Wave o ZigBee.
Este modelo se usa habitualmente en sistemas IoT residenciales como, por ejemplo, bombillas, interruptores, termostatos, cerraduras etc.
Estos sistemas envían pequeñas cantidades de información en forma de mensaje de bloqueo de una puerta, o de comando para encender una luz, por lo que sus requisitos en cuanto a tasa de transmisión, son bajos.
Un inconveniente de este modelo es que algunos fabricantes desarrollan mecanismos de seguridad o de confianza propios que integran en los dispositivos, o bien, utilizan modelos de datos específicos. Esta falta de estandarización, puede limitar la capacidad de elección de los usuarios. Si quieren que un nuevo dispositivo se comunique con los que tiene ya instalados, éste debe ser de la misma familia. Por tanto, el usuario se ve «atado» al fabricante de los dispositivos que escogió en primer lugar.
2 Dispositivo conectado a la nube, como en tu Smart-TV
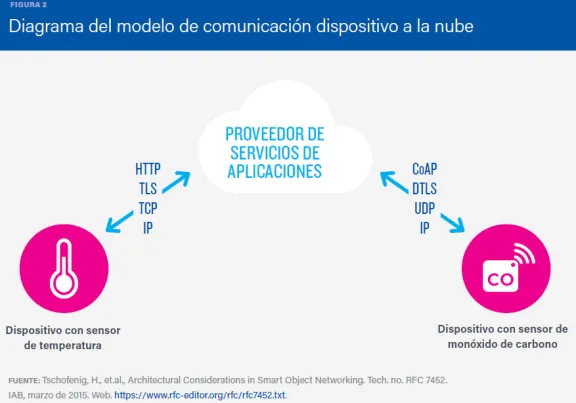
En este segundo modelo, el dispositivo se conecta directamente a un servicio en la nube, usando conexiones Wi-Fi o red ethernet (los mecanismos de comunicación de que se disponga) para conectarse a la red IP. Este modelo, aporta más valor al usuario, ya que amplía las capacidades del dispositivo más allá de sus características nativas.
Por ejemplo, un termostato inteligente conectado a la nube puede ser controlado de forma remota, a través de un teléfono móvil o una interfaz web. También puede recibir actualizaciones remotas de software. Y, otro aspecto muy interesante para el usuario: la base de datos en la nube que almacena los datos transmitidos por el termostato, ofrece analíticas de consumo que permiten mejorar su eficiencia. Por tanto, un termostato inteligente nos permite ahorrar energía y abaratar así la factura.
Otro ejemplo muy conocido son las SmartTV, que utilizan la conexión a Internet para poder hacer cosas como activar el reconocimiento de voz de la televisión.
Como siempre, la integración de dispositivos de distintos fabricantes puede crear problemas de interoperabilidad. Por ejemplo, cuando se utilizan protocolos de datos propietarios en la comunicación entre el dispositivo y el servicio en la nube, el usuario puede quedar «atado» a ese proveedor (vendor lock-in). Este hecho no sólo afecta a la capacidad de elección del usuario a la hora de conectar nuevos dispositivos, sino también, a cuestiones relacionadas con la propiedad o el acceso a los datos.
3 Dispositivo a puerta de enlace, como en los wearables para deportes
En este tercer modelo de comunicación, los dispositivos se conectan a la nube a través de otro dispositivo que hace de puerta de enlace o intermediario. Éste último puede ser un smartphone o un dispositivo tipo hub, en el que un software de aplicación provee de funcionalidades de seguridad o traducción de protocolos o datos.
Un ejemplo de dispositivos que utilizan este modo de conexión son los dispositivos vestibles (o wearables) que se utilizan para hacer deporte. Estos dispositivos no suelen tener capacidad nativa para conectarse a Internet. Como puerta de enlace local, utilizan un teléfono inteligente con una aplicación que facilita la comunicación y transmisión de datos entre el dispositivo y un servicio en la nube.
De esta forma, por ejemplo, puedes registrar y controlar tus entrenamientos, compartirlos con quien tu quieras o colaborar con una causa solidaria, convirtiendo tus pasos en donaciones.
Este modelo permite reducir los problemas de interoperabilidad entre dispositivos, ya que un mismo hub puede tener instalados transceptores de distintas familias de dispositivos.
También, permite conectar objetos que no utilizan el protocolo IP, y por tanto no pueden conectarse directamente a Internet. O integrar nuevos dispositivos que sólo soportan IPv6, con dispositivos y servicios antiguos que utilizan la versión anterior IPv4.
Sin embargo, este modelo también tiene su contrapartida. La principal es el mayor coste y complejidad asociados al desarrollo del software y el sistema para la puerta de enlace de capa de aplicación. No obstante, si se consigue que en el diseño de nuevos dispositivos IoT se utilicen protocolos genéricos, en el futuro se desplegarán más puertas de enlace genéricas, con una estructura más sencilla y un menor costo, que facilitará la interconexión entre dispositivos.

4 Dispositivo conectado a través de back-end
Este cuarto modelo es una extensión del modelo 2, comunicación de un dispositivo único a la nube, permitiendo que los usuarios exporten y analicen datos de objetos inteligentes de un servicio en la nube en combinación con datos de otras fuentes. Esta estrategia permite romper los silos de datos que se generan en el modelo «dispositivo conectado a proveedor de servicios de internet único«.
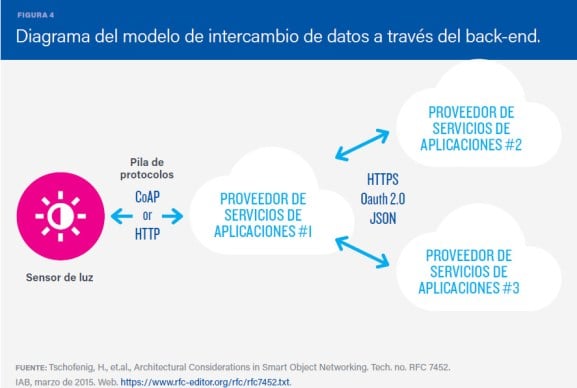
Una arquitectura de intercambio de datos a través del back-end permite , acceder y analizar fácilmente en la nube a los datos producidos por toda la gama de dispositivos desplegados en un edificio.
Por otra parte, este tipo de arquitectura facilita la portabilidad de los datos, permitiendo a los usuarios mover sus datos al cambiar de servicio IoT.
Conclusión
Además de por ciertas consideraciones técnicas, el uso de uno u otro modelo tendrá mucho que ver con la naturaleza abierta o propietaria de los dispositivos IoT que se conecten en la red. Lo que está claro, es que las interoperabilidad entre dispositivos y el uso de estándares abiertos son aspectos clave en el diseño de sistemas de la Internet de las Cosas.
Por otra parte, los modelos que permiten la aplicación de analíticas machine learning a los datos de dispositivos almacenados en la nube, generan mucho valor para el usuario final, ya que le permiten hacer uso de nuevas formas de usar la información. No obstante, no hay que olvidar el coste que puede tener el conectar los dispositivos a la nube en regiones donde los costes de conectividad son elevados.
Estos nuevos flujos de datos se pueden aprovechar para diseñar nuevos productos y servicios que actúen como auténticos catalizadores de la innovación.
Post original publicado en ThinkBig Empresas
Referencias:
La Internet de las Cosas— Una breve reseña (ISOC)
https://www.iotcentral.io/blog/the-iot-architecture-at-the-edge















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}